When it comes to microservice based SaaS applications, service discovery has an important role in making the application work properly. In a traditional application running on physical hardware, the network locations of service instances are relatively static. But, in a modern, cloud‑based microservices application service instances have dynamically assigned network locations, because the set of service instances changes dynamically because of autoscaling, failures, and upgrades
There are two main service discovery patterns: client‑side discovery and server‑side discovery.
The Client‑Side Discovery Pattern
In this type of pattern, the client is responsible for determining the network locations of available service instances and load balancing requests across them.
The client queries a service registry, which is a database of available service instances, and then uses a load‑balancing algorithm to select one of the available service instances and makes a request.
The network location of a service instance is registered with the service registry when it starts up. It is removed from the service registry when the instance terminates

The service instance’s registration is typically refreshed periodically using a heartbeat mechanism
There are a few advantages, as well as some disadvantages when using the Client‑Side discovery pattern. The main benefit is that this pattern is relatively straightforward (except for the service registry). And the main drawback is that the Client is coupled with the service registry therefore you must implement client‑side service discovery logic for each programming language and framework used by your service clients.
The Server‑Side Discovery Pattern

In this approach, the client makes a request to a service via a load balancer. The load balancer then queries the service registry and routes each request to an available service instance. As with client‑side discovery, service instances are registered and deregistered with the service registry
The advantages from using this approach are:
- Details of discovery are abstracted away from the client
- Clients simply make requests to the load balancer
- This eliminates the need to implement discovery logic for each programming language and framework used by your service clients
One main disadvantage is the Load balancer, a new component that needs to be set up and managed.
The Service Registry
The service registry is a database containing the network locations of service instances, and is a key part of service discovery. A service registry needs to be highly available and up to date. Some examples of service registries include:
Service Registration Options
The service instances must be registered with and deregistered from the service registry. There are a couple of different ways to handle the registration and deregistration:
- self‑registration pattern
- some other system component to manage the registration of service instances, the third‑party registration pattern
The Self‑Registration Pattern
In the Self‑Registration Pattern, the service instance is responsible for registering and deregistering itself with the service registry. The service instance sends heartbeat requests to prevent its registration from expiring
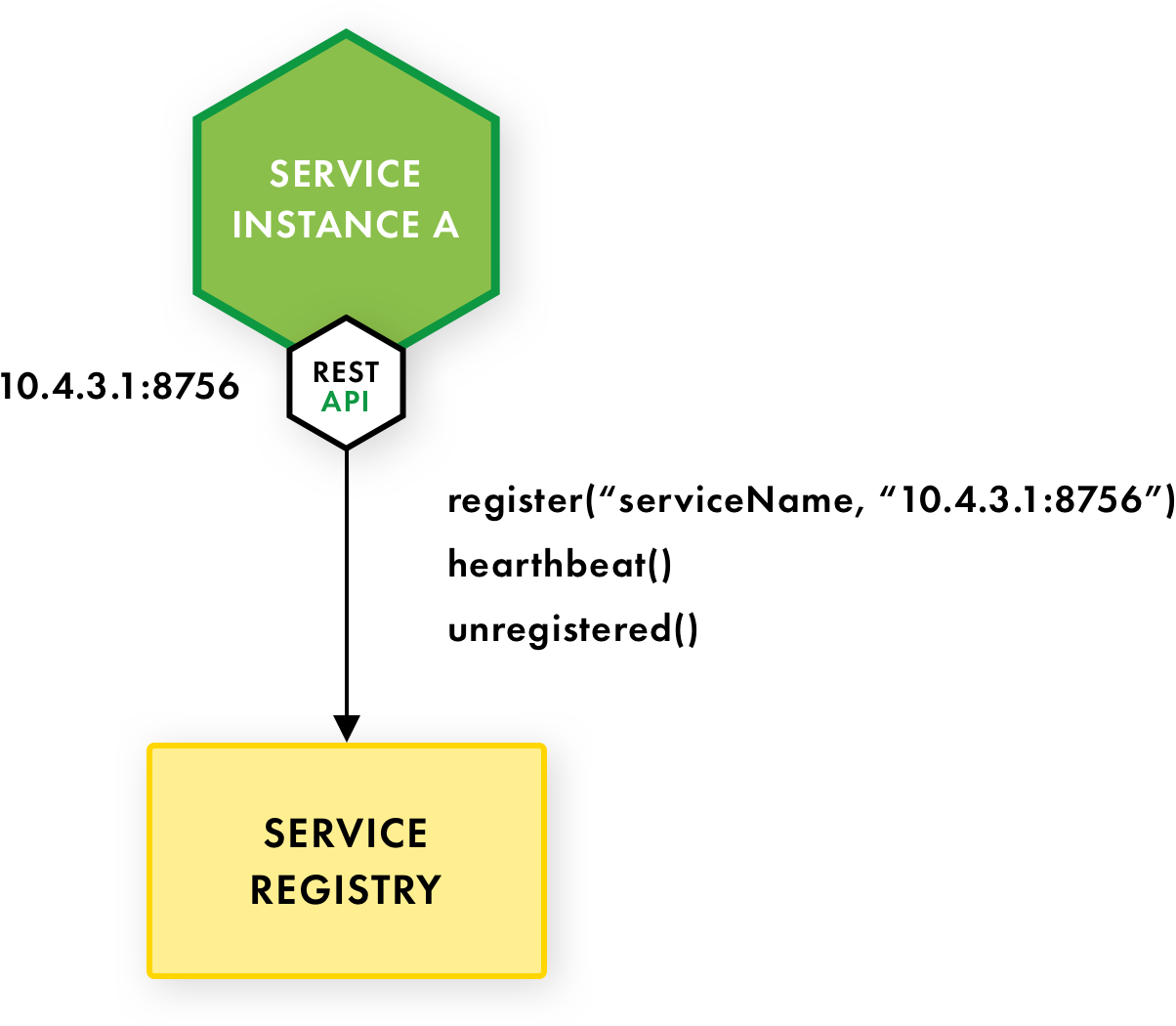
The benefit from this approach is that it is relatively simple and doesn’t require any other system components. The drawback is that it couples the service instances to the service registry. You must implement the registration code in each programming language and framework used by your services.
The Third‑Party Registration Pattern
In this pattern, the service instances aren’t responsible for registering themselves with the service registry. Another system component known as the service registrar handles the registration, and when it notices a newly available service instance it registers the instance with the service registry. The service registrar also deregisters terminated service instances

This is one example of a service registrar is the open source Registrator project. It automatically registers and de-registers service instances that are deployed as Docker containers. Registrator supports several service registries, including etcd and Consul.
The benefit from this approach is that the services are decoupled from the service registry. On the other hand, the drawback is that there is another component to be set up and managed.
Those are the main things you should know about service discovery. Let us us know in the comments if you have any questions, and (if you haven’t already) make sure to read the previous parts of this SaaS blog series: Intro to Software as a Service, Monoliths vs. Microservices and Interacting with the microservices.



